Simulation on Reconfigurable Heterogeneous Computer Architectures
06.2008 - 10.2017, SimTech Cluster of Excellence
Overview
Since the beginning of the DFG Cluster of Excellence "Simulation Technology" (SimTech) (EXC 310/1) at the University of Stuttgart in 2008, the Institute of Computer Architecture and Computer Engineering (ITI, RA) is an active part of the research within the Stuttgart Research Center for Simulation Technology (SRC SimTech). The institute's research includes the development of fault tolerant simulation algorithms for new, tightly-coupled many-core computer architectures like GPUs, the acceleration of existing simulations on such architectures, as well as the mapping of complex simulation applications to innovative reconfigurable heterogeneous computer architectures.
Within the research cluster, Hans-Joachim Wunderlich acts as a principal investigator (PI) and he co-coordinates the research activities of the SimTech Project Network PN2 "High-Performance Simulation across Computer Architectures". This project network is unique in terms of its interdisciplinary nature and its interfaces between the participating researchers and projects. Scientists from computer science, chemistry, physics and chemical engineering work together to develop and provide new solutions for some of the major challenges in simulation technology. The classes of computational problems treated within project network PN2 comprise quantum mechanics, molecular mechanics, electronic structure methods, molecular dynamics, Markov-chain Monte-Carlo simulations and polarizable force fields.


Project Overview
The ongoing semiconductor technology scaling impels the integration of highly diversified computer architectures with different kinds of processing cores, communication channels and embedded memories. Besides classic CPU and data-parallel GPU cores, runtime reconfigurable units emerge as integrated part of such architectures.
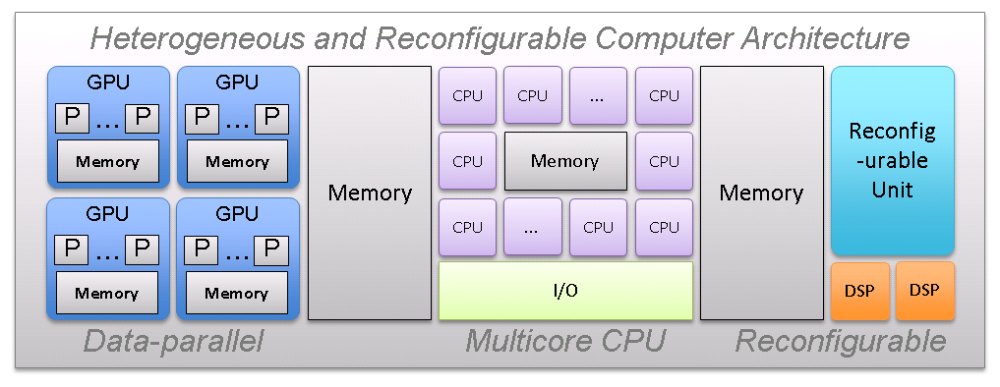
Simulation technology will benefit significantly from these emerging computer architectures since they will close the gap between serial or coarse-grained parallel tasks on CPU cores and highly data-parallel tasks on GPU cores. Reconfigurable units can change their functionality at runtime and hence adapt dynamically to the needs of simulation applications. However, the upcoming architectural advances will be accompanied by a significant increase of complexity on the software side. For example, the shift from serial programming to parallel programming of multiple processors (CPUs), or the use of graphics processing units (GPUs) introduces new programming paradigms, which increasingly reflect and exhibit particular aspects of the underlying hardware structures.
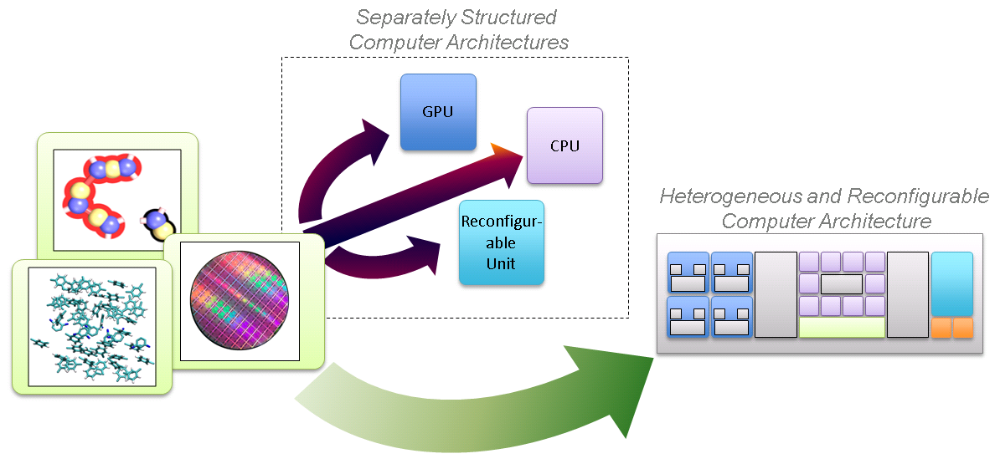
Consequently, algorithms have to be analyzed with a much stronger focus to the available hardware structures. Furthermore, algorithmic parts have to be identified and isolated to deduce compute modules for optimal matching architectures. The combination of different computing resources in a reconfigurable heterogeneous architecture demands sophisticated loadbalancing and adaption to changing system conditions (e.g. changing availability of computing resources).
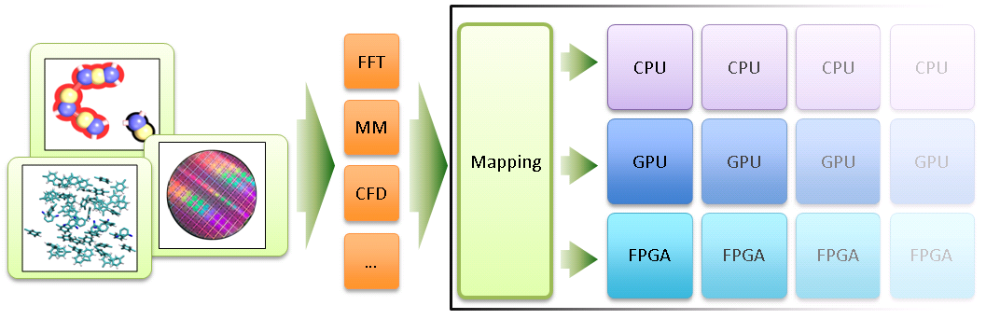
In this project, we develop new methods that enable the direct mapping of simulation applications to innovative reconfigurable heterogeneous computer architctures. This includes methods for the assisted analysis and partitioning of algorithms, the deduction and design of compute modules and integrated software infrastructure for runtime load-balancing and adaption.

Project Overview
Computer simulations drive innovations in science and industry, and they are gaining more and more importance. However, their extraordinary high computational demand generates significant challenges for contemporary computing systems. Typical high-performance computing systems, which provide sufficient performance and high reliability, are extremely expensive.
Modern many-core processor architectures like graphics processors (GPUs) offer high computational performance at very low costs, and they enable scientific simulation applications on the researcher's desktop. However, being designed for the graphics mass-market, GPUs offer only limited fault tolerance measures (e.g. ECC-protected memory) to cope with the increasing vulnerability to transient effects (soft errors) and other reliability threats. To fulfill the strict reliability requirements in scientific computing and simulation technology, appropriate fault tolerance measures have to be integrated into simulation algorithms and applications on GPUs. Algorithm-Based Fault Tolerance has the potential to meet these requirements.
The research within the first project phase (Mapping Simulation Algorithms to NoC-MPSoC Computers) concentrates on the development of fault tolerant algorithms for GPU architectures and their integration into scientific simulation applications. Moreover, sophisticated simulations tasks from partners within the Cluster and Project Network PN2 are analyzed and adapted or re-designed for GPU architectures.
Acceleration of Monte-Carlo Molecular Simulations on Hybrid Computing Architectures
Stochastic-based simulation methods play an important role since they allow the solution of problems that tend to be very hard to be solved by deterministic algorithms. For search and optimization problems, evolutionary and genetic algorithms have been applied. Simulated annealing has been used to localize globally optimal problem solutions. One of the most important classes of such techniques are Monte Carlo (MC) methods, which approximate solutions for quantitative problems, with multiple coupled degrees of freedom, by random sampling. The problem, which is targeted in this work, is the parallelization of molecular simulations of the grand canonical ensemble, from the field of thermodynamics, on hybrid computing systems.

It can be shown, that these simulations are an instance of a special case of MC methods, the Markov-Chain Monte-Carlo (MCMC) simulation. Being the core of many tasks in thermodynamics, Monte-Carlo Molecular Simulations often forms the major bottleneck, which is typically tackled by coarse-grained parallelization and distribution of simulation instances on clusters or workstation grids. Commonly, this is associated with considerable overhead and costs. In our interdisciplinary collaboration with the Institute of Thermodynamics and Thermal Process Engineering we developed new methods for the parallel mapping and implementation of Markov-Chain Monte-Carlo molecular simulations on hybrid CPU-GPGPU systems. The mapping is characterized by data-parallel energy calculations and speculative computations in each Monte-Carlo step. The mapping is able to directly utilize the different architectural characteristics of hybrid computing systems.
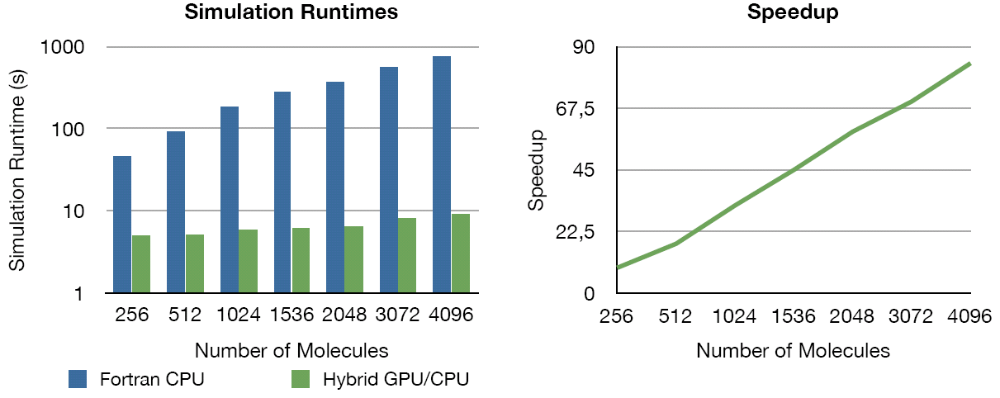
It was shown that the parallel mapping achieves speedups of more than 87x. This significant speedup enables MCMC molecular simulations at workstation-level and the investigation of problem sizes, which previously required computing clusters or grid-based systems.
Evaluation of the Apoptotic Receptor-Clustering Process
Apoptosis, the prototype of programmed cell death allows multi-cellular organisms to remove damaged or infected cells. A profound understanding of the molecular mechanisms involved in this important physiological process is required for the control of cell death, especially focused on the initiation of the apoptotic signaling pathways. One of these signaling pathways is the extrinsic pro-apoptotic signaling pathway, which is initiated by signal competent clusters of e.g. tumor necrosis factor (TNF) receptors and the corresponding TNF ligands.
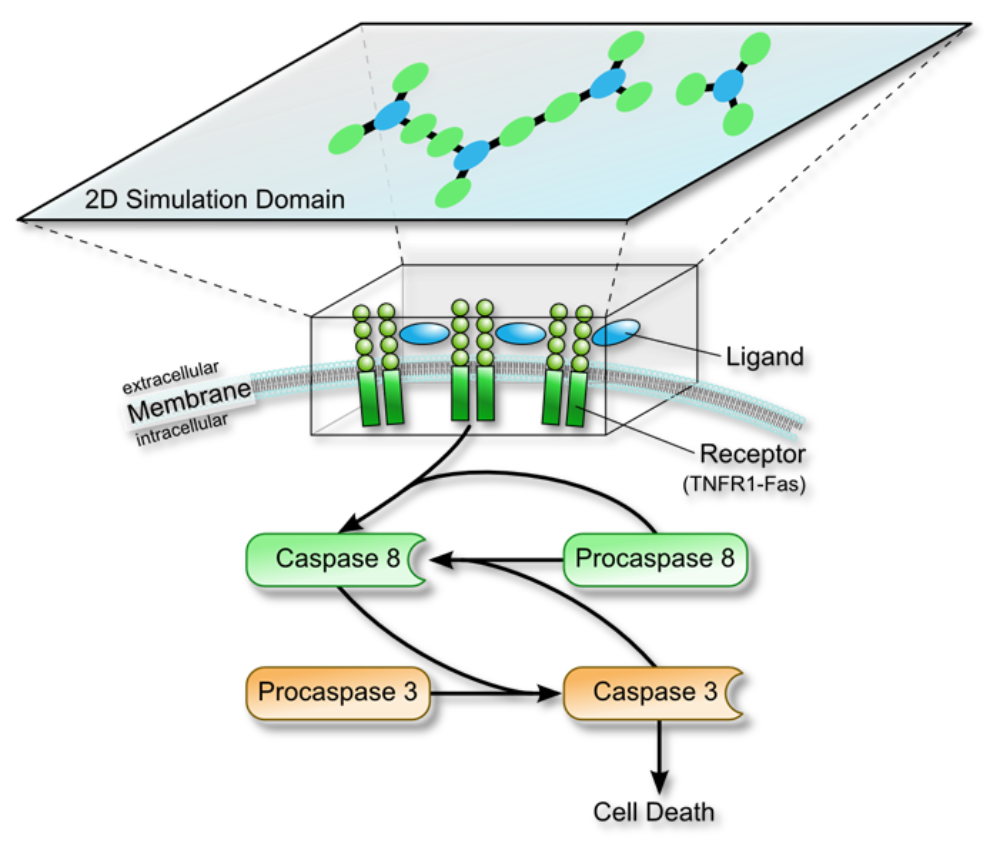
In recent years, different mathematical models have been developed in order to describe and simulate the formation of signal competent clusters consisting of receptors and their ligands. In our interdisciplinary collaboration with the Institute of Analysis, Dynamics, and Modeling and the Institute of Cell Biology and Immunology, we developed an efficient, parallel mapping of a novel mathematical model to a modern GPGPU many-core architecture. This model evaluates the apoptotic receptor-clustering on the cell membrane. Besides the translation of the receptors and ligands, the model additionally incorporates rotations. The model is based on a derivation of a nonlinearly coupled system of stochastic differential equations for the motion of the receptors and ligands. The system is solved by a Euler-Maruyama approximation. Due to the high costs of the simulation, the tailoring step to GPU many-core architectures was inevitable. Our efficient, parallel mapping exploits fine-grained intra-GPU parallelism with multiple active simulation instances per GPGPU device, as well as coarse-grained inter-GPU parallelism by utilizing all available GPGPU devices within a system.

The parallel evaluation algorithm for the mathematical model yields peak speedups of up to 400x relative to a grid-based implementation on a multi-core CPU. This finally reduces the computation times from months to days or hours.
Activities
- H.-J. Wunderlich: "Fault Tolerance Meets Diagnosis", Keynote at the 21st IEEE International On-Line Testing Symposium (IOLTS), Elia, Halkidiki, Greece, July 6-8, 2015
Journals and Conference Proceedings
2017
- Energy-efficient and Error-resilient Iterative Solvers for Approximate Computing. Alexander Schöll; Claus Braun and Hans-Joachim Wunderlich. In Proceedings of the 23rd IEEE International Symposium on On-Line Testing and Robust System Design (IOLTS′17), Thessaloniki, Greece, 2017, pp. 237–239. DOI: https://doi.org/10.1109/IOLTS.2017.8046244
2016
- Applying Efficient Fault Tolerance to Enable the Preconditioned Conjugate Gradient Solver on Approximate Computing Hardware. Alexander Schöll; Claus Braun and Hans-Joachim Wunderlich. In Proceedings of the IEEE International Symposium on Defect and Fault Tolerance in VLSI and Nanotechnology Systems (DFT′16), University of Connecticut, USA, 2016, pp. 21–26. DOI: https://doi.org/10.1109/DFT.2016.7684063
- Pushing the Limits: How Fault Tolerance Extends the Scope of Approximate Computing. Hans-Joachim Wunderlich; Claus Braun and Alexander Schöll. In Proceedings of the 22nd IEEE International Symposium on On-Line Testing and Robust System Design (IOLTS′16), Sant Feliu de Guixols, Catalunya, Spain, 2016, pp. 133–136. DOI: https://doi.org/10.1109/IOLTS.2016.7604686
- Efficient Algorithm-Based Fault Tolerance for Sparse Matrix Operations. Alexander Schöll; Claus Braun; Michael A. Kochte and Hans-Joachim Wunderlich. In Proceedings of the 46th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN′16), Toulouse, France, 2016, pp. 251–262. DOI: https://doi.org/10.1109/DSN.2016.31
2015
- Low-Overhead Fault-Tolerance for the Preconditioned Conjugate Gradient Solver. Alexander Schöll; Claus Braun; Michael A. Kochte and Hans-Joachim Wunderlich. In Proceedings of the International Symposium on Defect and Fault Tolerance in VLSI and Nanotechnology Systems (DFT′15), Amherst, Massachusetts, USA, 2015, pp. 60–65. DOI: https://doi.org/10.1109/DFT.2015.7315136
- Efficient On-Line Fault-Tolerance for the Preconditioned Conjugate Gradient Method. Alexander Schöll; Claus Braun; Michael A. Kochte and Hans-Joachim Wunderlich. In Proceedings of the 21st IEEE International On-Line Testing Symposium (IOLTS′15), Elia, Halkidiki, Greece, 2015, pp. 95–100. DOI: https://doi.org/10.1109/IOLTS.2015.7229839
2014
- A-ABFT: Autonomous Algorithm-Based Fault Tolerance for Matrix Multiplications on Graphics Processing Units. Claus Braun; Sebastian Halder and Hans-Joachim Wunderlich. In Proceedings of the 44th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN′14), Atlanta, Georgia, USA, 2014, pp. 443–454. DOI: https://doi.org/10.1109/DSN.2014.48
2013
- Efficacy and Efficiency of Algorithm-Based Fault Tolerance on GPUs. Hans-Joachim Wunderlich; Claus Braun and Sebastian Halder. In Proceedings of the IEEE International On-Line Testing Symposium (IOLTS′13), Crete, Greece, 2013, pp. 240–243. DOI: https://doi.org/10.1109/IOLTS.2013.6604090
2012
- Parallel Simulation of Apoptotic Receptor-Clustering on GPGPU Many-Core Architectures. Claus Braun; Markus Daub; Alexander Schöll; Guido Schneider and Hans-Joachim Wunderlich. In Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM′12), Philadelphia, Pennsylvania, USA, 2012, pp. 1–6. DOI: https://doi.org/10.1109/BIBM.2012.6392661
- Acceleration of Monte-Carlo Molecular Simulations on Hybrid Computing Architectures. Claus Braun; Stefan Holst; Hans-Joachim Wunderlich; Juan Manuel Castillo and Joachim Gross. In Proceedings of the 30th IEEE International Conference on Computer Design (ICCD′12), Montreal, Canada, 2012, pp. 207–212. DOI: https://doi.org/10.1109/ICCD.2012.6378642
2010
- Algorithmen-basierte Fehlertoleranz für Many-Core-Architekturen; Algorithm-based Fault-Tolerance on Many-Core Architectures. Claus Braun and Hans-Joachim Wunderlich. it - Information Technology 52, (August 2010), pp. 209–215. DOI: https://doi.org/10.1524/itit.2010.0593
- Algorithm-Based Fault Tolerance for Many-Core Architectures. Claus Braun and Hans-Joachim Wunderlich. In Proceedings of the 15th IEEE European Test Symposium (ETS′10), Praha, Czech Republic, 2010, pp. 253. DOI: https://doi.org/10.1109/ETSYM.2010.5512738
Workshop Contributions
2016
- Hardware/Software Co-Characterization for Approximate Computing. Alexander Schöll; Claus Braun and Hans-Joachim Wunderlich. In Workshop on Approximate Computing, Pittsburgh, Pennsylvania, USA, 2016.
2015
- ABFT with Probabilistic Error Bounds for Approximate and Adaptive-Precision Computing Applications. Claus Braun and Hans-Joachim Wunderlich. In Workshop on Approximate Computing, Paderborn, Germany, 2015.
2014
- A-ABFT: Autonomous Algorithm-Based Fault Tolerance on GPUs. Claus Braun; Sebastian Halder and Hans-Joachim Wunderlich. In International Workshop on Dependable GPU Computing, in conjunction with the ACM/IEEE DATE′14 Conference, Dresden, Germany, 2014.

Hans-Joachim Wunderlich
Prof. Dr. rer. nat. habil.Research Group Computer Architecture,
retired