Deep neural networks for model and model parameter extraction from 3D computed tomography data.


Computed tomography (CT) is one of the relatively few methods of 3D imaging which makes it possible to simultaneously capture both the outer shape and the inner structures of objects. Therefore, 3D models or model parameters of the objects can be extracted from CT volume data (see figures on the left). From the CT data, the models are generated using modern algorithms of digital image processing based on artificial intelligence. In recent years, it has been demonstrated for many problems in digital image processing and the field of computer vision that deep neural networks can achieve better results compared to previously established algorithmic approaches. This is especially true for computed tomography data, which are typically very noisy and affected by artifacts.
The geometric model of a passive electrical circuit is demonstrated in video1 and the geometric model of an Ethernet connector in video2 . Both models were extracted from CT data generated by the department's computed tomography scanner. Further information on this research area can be found here.
A deep neural network for model parameter extraction from two CT datasets
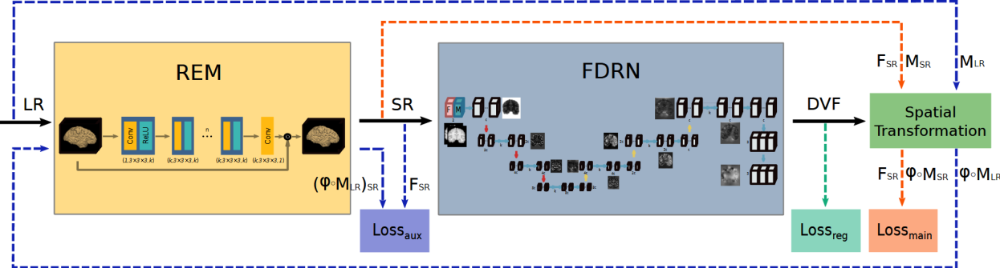
With the FDRN neural network, the deformation of an object is determined as a model parameter starting from two CT images between which the object is deformed. For example, a deformation of a battery structure due to its aging occurs because of the charging and discharging cycles between two CT images before and after the introduced aging process. To increase the accuracy of the above model parameter values, a second neural network SEM is added upstream to increase the resolution (super-resolution).
Artifact reduction using deep neural networks in computed tomography

The 3D volume data of computed tomography are generally subject to strong artifacts (smearing of edges, streaking, attenuation of the gray value intensity in and between objects, see image above left). A wide variety of artifacts can be compensated with remarkably high quality on the basis of deep neural networks. Neural networks also have the advantageous property that the high computing time requirement for training the neural networks is spent offline - i.e. just before the CT reconstruction (computation) of each CT data set. Alternative methods to neural networks that reduce artifacts are often based on iterative CT reconstruction. These are orders of magnitude more computationally expensive and are incurred in the reconstruction of each CT data set. More information on this topic can be found here.
Parallel real-time data processing and reduction for broadband sensor data streams


Broadband sensor data streams (e.g. more than 1GB/s, see figure on the left), as they are generated in imaging sensor systems with high frame rates, are reduced by more than 3 orders of magnitude by means of parallel feature or object extraction on so-called field-programmable gate arrays (FPGAs) directly at the sensor system. For this purpose, matched algorithms and architectures are developed to determine the connected components of objects in the images acquired by the sensor system. The proposed algorithms and architectures are suitable for FPGAs and are implemented with the goal of high data throughput. Using hardware modeling language VHDL, the architectures are implemented in a resource efficient manner on the FPGAs that are integrated into the sensor system. With the implemented architectures, features in general - in the case shown, droplet sizes and shapes as well as filament lengths - can be determined in real time in the adjacent FPGA-based sensor system at 1 000 to 10 000 frames/s). The significantly reduced amount of feature data is transmitted to the host PC without pixel data. Further information on this topic can be found here.
A recurrent neural network for video super-resolution implemented on an FPGA
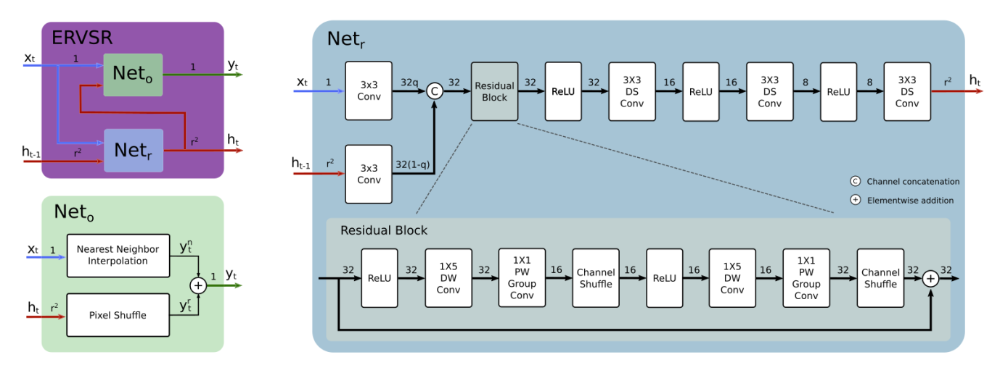
A neural network for video super-resolution implemented on an FPGA that achieves 76 fps for 4K UHD images. The neural network implementation can be integrated on an FPGA in the camera shown above.
Lightweight real-time compression of large data sets in imaging systems


The focus of the work is on algorithms and architectures for lightweight real-time compression of large amounts of data in fast 2D imaging and 3D imaging that do not result in a reduction of the performance of the imaging systems (further steps in data processing and data transport). In this respect, the primary goal is to realize compression methods with low computational complexity and small latency, while the compression ratio is another goal with lower priority. For fast 2D imaging, the hardware modeling language VHDL is used to implement the architectures on so-called field-programmable gate arrays (FPGAs). Such FPGAs are based on reconfigurable architectural elements with fine granularity, which are particularly suitable for the irregular algorithms of real-time compression methods.
In 3D computed tomography, the increasing resolutions of detectors lead to 3D volume data sets up to the TB range for a CT image. With irregular data structures for the volume data sets, the data volumes for planar objects (such as circuit boards) or 2D objects (e.g., hollow cylinders) can be reduced by two orders of magnitude, i.e., from the three-digit GB to the TB range to the one- to two-digit GB range. In addition, lossless compression techniques can further compress the resulting data sets. The reduction of data volumes in computed tomography is essential for the further increase of resolutions. Further information on the subject area can be found here.
Multispectral computed tomography for laboratory µCT scanners and synchrotrons

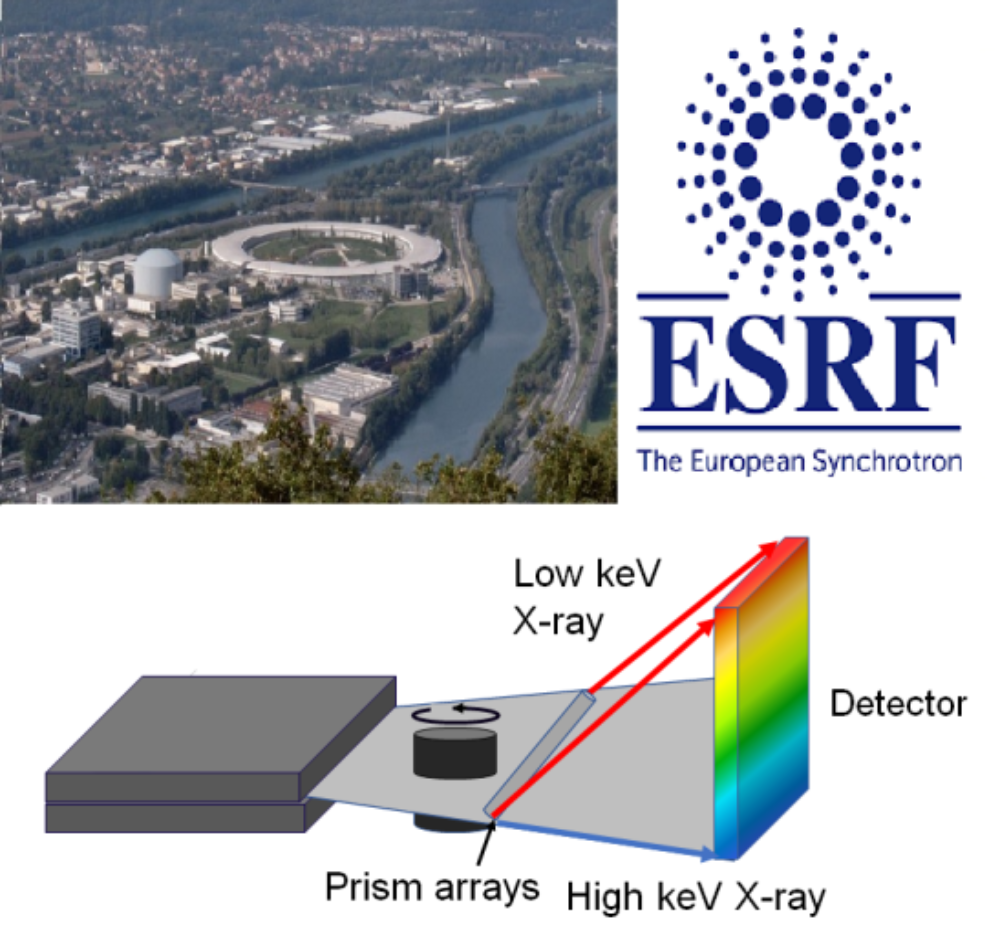
Classical computed tomography is based on gray-scale intensity images, with the help of which internal structures of objects can be displayed and analyzed. In contrast, multispectral CT imaging (like color imaging in optics) enables improved both qualitative and quantitative evaluation of CT images with respect to materials. By means of so-called energy-sensitive detectors, which detect individual photons including their photon energy, multispectral CT is feasible in principle. The most powerful energy-sensitive detector to date is currently being integrated into the department's computed tomography scanner shown above left. The improved imaging based on multispectral imaging will be used to extract more accurate models.
As an alternative to laboratory computed tomographs, synchrotons (electron storage rings such as the ESRF www.esrf.de) are used as monochromatic photon sources of highest brilliance for imaging. A total of 18 countries jointly support the European Synchrotron ESRF, thus ensuring their researchers access to one of the three most powerful photon sources in the world. Every year, more than 1000 scientists from Germany come to the ESRF to use imaging to analyze their samples. For more information on the topic, click here.