Tiefe neuronale Netze für die Modellparameter- und Modell-Extraktion aus 3D-Computertomographie-Daten


Die Computertomographie (CT) ermöglicht es – als eines der wenigen Verfahren der 3D-Bildgebung – gleichzeitig sowohl die äußere Form als auch die inneren Strukturen von Objekten zu erfassen. Deshalb können aus CT-Volumendaten 3D-Modelle bzw. Modell-Parameter der Objekte extrahiert werden (siehe Abbildungen links). Aus den CT-Daten werden die Modelle mit modernen Algorithmen der digitalen Bildverarbeitung auf Basis künstlicher Intelligenz erzeugt. In den letzten Jahren wurde für viele Fragestellungen in der digitalen Bildverarbeitung und dem Bereich Computer Vision nachgewiesen, dass tiefe neuronale Netzen gegenüber den bisher etablierten algorithmischen Ansätzen bessere Ergebnisse erzielen können. Dies gilt insbesondere für die Daten der Computertomographie, die typischerweise sehr stark verrauscht und artefaktbehaftet sind.
Das geometrische Modell einer passiven elektrischen Schaltung wird in Video1 und das geometrische Modell eines Ethernet-Steckers in Video 2 demonstriert. Beide Modelle wurden aus CT-Daten extrahiert, die mit dem Computertomographen der Abteilung erzeugt wurden.
Weiterführende Information zu diesem Forschungsbereich finden Sie hier.
Ein tiefes neuronales Netz zur Modellparameter-Extraktion aus zwei CT-Datensätzen
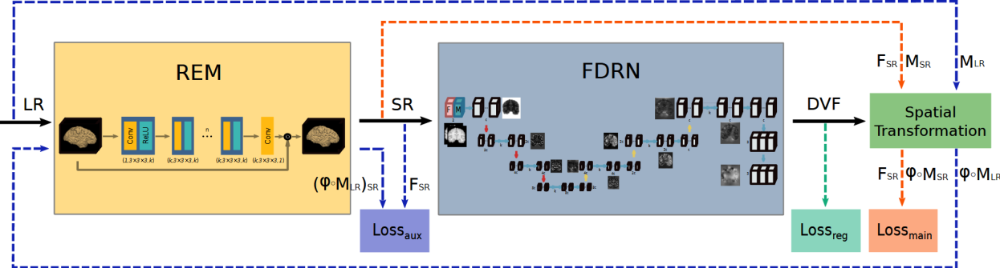
Mit dem neuronalen Netz FDRN wird die Deformation eines Objekts als Modellparameter ausgehend von zwei CT-Aufnahmen bestimmt, zwischen denen das Objekt deformiert wird. Beispielsweise findet eine Deformation einer Batterie-Struktur durch ihre Alterung aufgrund der Auf- und Entladezyklen zwischen zwei CT-Aufnahmen vor und nach dem eingebrachten Alterungsprozess statt. Um die Genauigkeit der obigen Modellparameterwerte zu erhöhen wird ein zweites neuronales Netz REM zur Auflösungserhöhung (Superresolution) vorgeschaltet.
Artefaktreduktion mittels tiefer neuronaler Netze in der Computertomographie

Die 3D-Volumendaten der Computer-tomographie sind grundsätzlich stark artefaktbehaftet (Verschmierungen von Kanten, Streifenbildung, Abschwächungen der Grauwert-Intensität in und zwischen Objekten, siehe Bild oben links). Unterschiedlichste Artefakte lassen sich mit bemerkenswert hoher Qualität auf Basis tiefer neuronaler Netze kompensieren. Neuronale Netze haben darüber hinaus die vorteilhafte Eigenschaft, dass der hohe Rechenzeitbedarf beim Training der neuronalen Netze offline – also einmalig vor der CT-Rekonstruktion (Berechnung) jedes CT-Datensatzes – anfällt. Zu neuronalen Netzen alternative Verfahren, die die Artefakte reduzieren, basieren oftmals auf iterativer CT-Rekonstruktion. Diese sind um Größenordnungen rechenzeitaufwändiger und fallen bei der Rekonstruktion jedes CT-Datensatzes an.
Weiterführende Information zu diesem Themenbereich finden Sie hier.
Parallele Echtzeit-Datenverarbeitung und -reduktion für breitbandige Sensordatenströme


Breitbandige Sensordatenströme (z.B. mehr als 1GB/s, siehe Abbildung links), wie diese in bildgebenden Sensorsystemen mit hoher Bildwiederholrate entstehen, werden mittels paralleler Feature- oder Objekt-Extraktion auf sog. Field-Programmable-Gate-Arrays (FPGAs) unmittelbar am Sensorsystem um mehr als 3 Größenordnungen reduziert. Dazu werden simultan und abgestimmt aufeinander Algorithmen und Architekturen entwickelt, die zur Bestimmung der Zusammenhangs-Komponenten von Objekten in den Bildern dienen, die mit dem Sensorsystem aufgenommen werden. Die vorgeschlagenen Algorithmen und Architekturen sind für FPGAs geeignet und werden mit dem Ziel eines hohen Datendurchsatzes realisiert. Mittels Hardware-Modellierungssprache VHDL werden die Architekturen ressourceneffizient auf den FPGAs, die in das Sensorsystem integriert sind implementiert. Mit den implementierten Architekturen lassen sich allgemein Features – in dem dargestellten Fall Tropfengrößen und -formen sowie Fadenlängen - im nebenstehenden FPGA-basierten Sensorsystem bei 1 000 bis 10 000 Bilder/s) in Echtzeit ermitteln. Die signifikant reduzierte Menge der Feature-Daten werden an den Host-PC ohne Pixeldaten übertragen.
Weiterführende Information zu diesem Themenbereich finden Sie hier
Ein rekurrentes neuronales Netz für Video-Superresolution implementiert auf einem FPGA
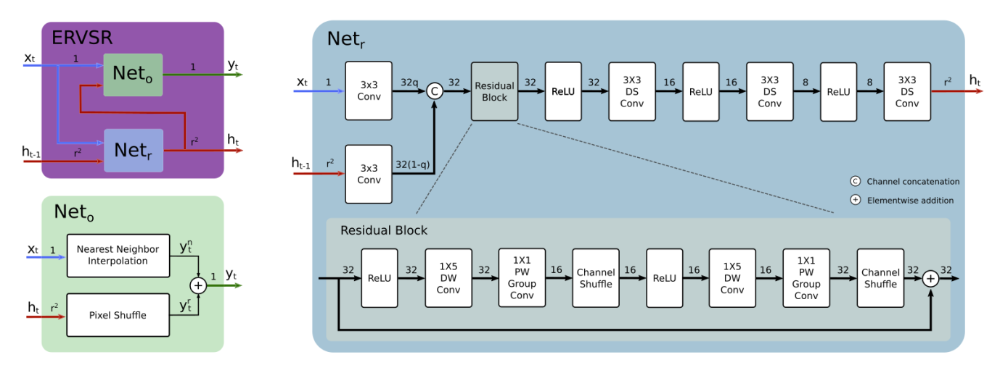
Ein neuronales Netz für Video-Superresolution, implementiert auf einem FPGA, das 76 Bilder/s für 4K-UHD-Bilder erreicht. Die Implementierung des neuronalen Netzes kann auf einem FPGA in die oben dargestellte Kamera integriert werden.
Leichtgewichtige Echtzeit-Kompression großer Datenmengen in bildgebenden Systemen


Gegenstand der Arbeiten sind Algorithmen und Architekturen für die leichtgewichtige Echtzeit-Kompression großer Datenmengen in der schnellen 2D-Bildgebung und der 3D-Bildgebung, die keine Reduktion der Performance der bildgebenden Systeme (weitere Schritte in der Datenverarbeitung und des Datentransports) zur Folge haben. Insofern ist das primäre Ziel, Kompressionsverfahren mit geringem Berechnungsaufwand und kleiner Latenzzeit zu realisieren, während die Kompressionsrate ein weiteres Ziel mit geringerer Priorität ist. Für die schnelle 2D-Bildgebung werden mit der Hardware-Modellierungssprache VHDL die Architekturen auf sog. Field-Programmable-Gate-Arrays (FPGAs) implementiert. Solche FPGAs basieren auf rekonfigurierbaren Architekturelementen mit feiner Granularität, die für die irregulären Algorithmen von Kompressionsverfahren in Echtzeit besonders geeignet sind.
In der 3D-Computertomographie führen die steigenden Auflösungen der Detektoren zu 3D-Volumendatensätzen bis in den TB-Bereich für eine CT-Aufnahme. Mit irregulären Datenstrukturen für die Volumendatensätze können die Datenmengen für planare Objekte (wie Platinen) bzw. 2D-Objekte (z.B. Hohlylinder) um zwei Größenordungen, d.h. vom dreistelligen GB- bis zum TB-Bereich in den ein- bis zweistelligen GB-Bereich reduziert werden. Zusätzlich können verlustlose Kompressionsverfahren die so erzeugten Datensätze weiter komprimieren. Die Reduktion der Datenmengen in der Computertomographie ist für die weitere Steigerung der Auflösungen essentiell. Weitere Informationen zu dem Themenbereich finden Sie hier.
Multispektrale Computertomographie für Labor-µCT-Scanner und Synchrotrons

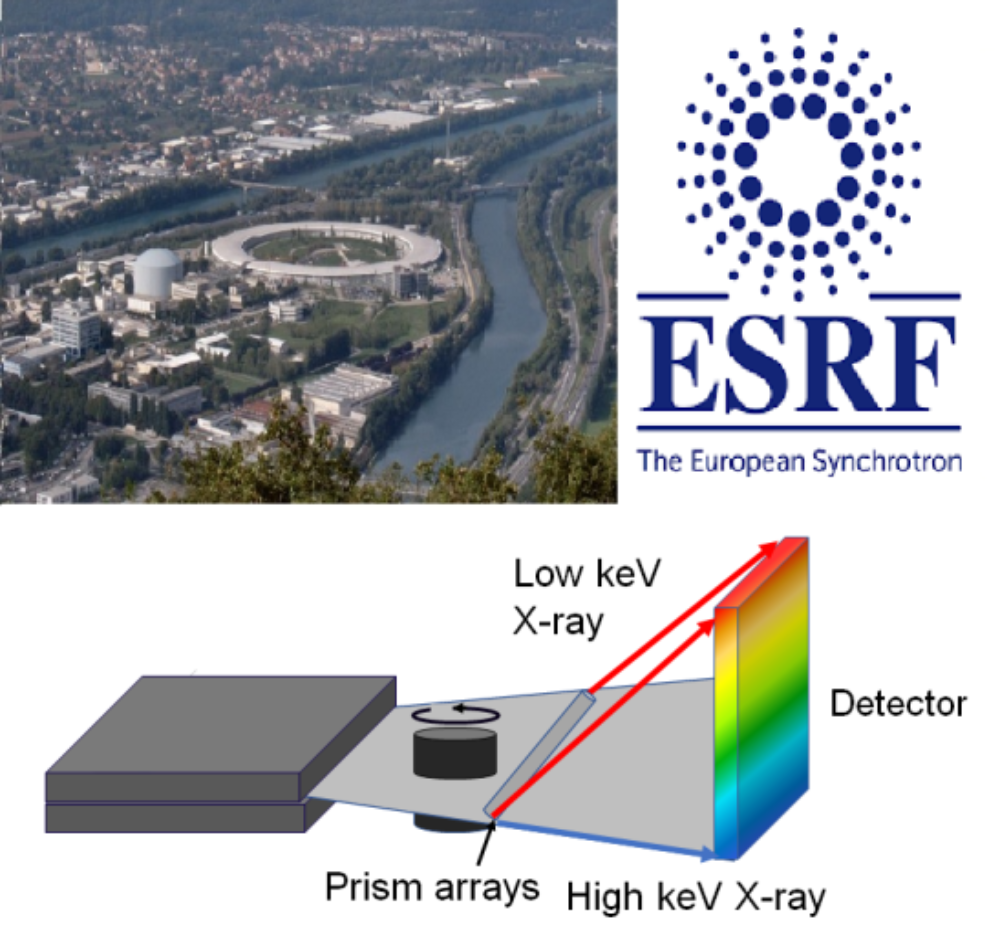
Die klassische Computertomographie basiert auf Grauwert-Intensitätsbildern, mit deren Hilfe innere Strukturen von Objekten dargestellt und analysiert werden können. Im Gegensatz dazu ermöglicht die multispektrale CT-Bildgebung (wie die Farbbildgebung in der Optik) eine verbesserte sowohl qualitative als auch quantitative Auswertung der CT-Aufnahmen hinsichtlich der Materialien. Mittels sog. energiesensitiver Detektoren, die einzelne Photonen inklusive ihrer Photonenenergie detektieren, ist prinzipiell eine multispektrale CT möglich. Der bisher leistungsstärkste energiesensitive Detektor wird derzeit in den links oben dargestellten Computertomographen der Abteilung integriert. Die verbesserte Bildgebung auf Basis der multispektralen Bildgebung soll für die Extraktion genauerer Modelle verwendet werden.
Alternativ zu Labor-Computertomographen werden Synchrotons (Elektronenspeicherringe wie z.B. das ESRF www.esrf.de) als monochromatische Photonenquellen höchster Brillanz zur Bildgebung verwendet. Insgesamt 18 Staaten tragen das Europäische Synchrotron ESRF gemeinsam und sichern ihren Forschern damit den Zugang zu einer der drei stärksten Photonenquellen auf der Welt. Aus Deutschland kommen jährlich über 1000 Wissenschaftler an das ESRF, um mittels Bildgebung ihre Proben zu analysieren. Weitere Informationen zu dem Themenbereich finden Sie hier.